原文はこちら。
http://www.oracle.com/technetwork/articles/soa/fonnegra-storing-sca-metadata-1715004.html
作者について
Nicolás Fonnegra Martinez はOracleのPrincipal Consultantで、主としてOracle Fusion Middleware製品を担当し、Oracle SOA SuiteとService Component Architectureを使ってコンセプトやベストプラクティスを開発しています。
Markus Lohn はOracleのSOA/Integration Architectで特にSOA、Java EEテクノロジーを専門にしています。
対象の読者
この記事は、Service Component Architecture(SCA)コンポジットを実装、設計するソフトウェア開発者、ソフトウェアアーキテクトを対象にしています。読者はサービス指向アーキテクチャ(SOA)の原則、Oracle WebLogic Server、Oracle SOA Suite 11gのことを知っていることを前提とします。
はじめに
SCAはSOA Suite 11gから利用できるようになりました。このテクノロジーはSCAコンポジット内のSOAコンポーネントを組み合わせて統合し、設計、開発、デプロイ、維持管理を容易にしてくれます。SCAデプロイメントはメタデータ駆動です。つまりWSDLやXMLスキーマ、XMLなどといったメタデータアーティファクトがコンポジットの振る舞いを決めます。
コンポジットや各コンポジット間の依存性が増加するにつれて、全てのメタデータを適切に管理する必要が出てきます。この記事ではOracle Metadata Services(MDS)リポジトリをメタデータの中心ストレージとして利用することのメリットをご紹介します。MDSリポジトリはOracle Fusion Middlewareの中心であり、Oracle Application Development Framework (Oracle ADF)やOracle WebCenter、そしてOracle SOA Suiteといった種々のテクノロジーのメタデータを管理します。
この記事は3部に分け、まず第1部ではSCAとMDSの概要を、第2部ではリポジトリ内のSCAメタデータファイルの管理に役立つMDSのタスクについてご説明します。第3部ではSCAコンポジットをMDSリポジトリと組み合わせて開発する方法をお伝えします。
コンセプト
SCA
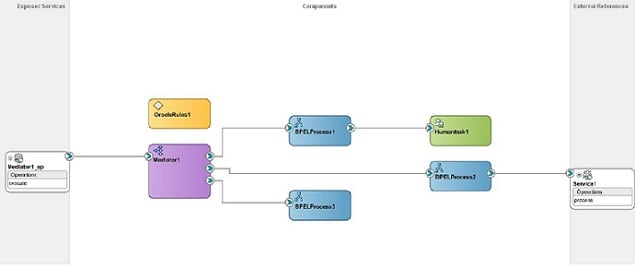
SCA標準はOracleを含む種々の企業が提唱し、現在ではOASISグループが維持管理しています。SCAはアプリケーションの作成やシステムの連係のためのソフトウェア開発モデルを提供します。SCAコンポジット内では、様々なコンポーネントが定義され、バインドされ、サービスを外部公開しています。SCAモデルの主要目的は複雑な機能、例えばビジネスプロセスを、固有のタスクを持つ小さなSOAコンポーネントに分解し、コンポーネントをコンポジットサービスとして統合して提供する、ということです。図1は開発時のSCAコンポジットの例です。
 |
| 図1 SCA Composite in Oracle JDeveloper |
こうしたSOAコンポーネントをハイレベルの中心コンポジットに構築、統合するフレームワークを提供し、SCAはSOA標準上で構築します。SCAコンポジットの主要な特性の一つは、メタデータ駆動である、ということです。つまり、各コンポーネントの振る舞いは単一のプログラミング言語(Java、C++、.NETランタイム上の言語など)ではなく、XMLファイルのようなメタデータアーティファクトで決まります。この特長により、SCAコンポジットは非常に柔軟になり、簡単にインターフェース定義に基づいた新しいコンポーネントと統合したり入れ替えたりできます。
SCAコンポジットを3部(コンポーネント、外部参照、公開サービス)に分けます。コンポーネント部分はSCAコンポジットの中心部分で、全てのコンポーネントやコンポーネント間の通信(ワイヤリング)を定義しています。Oracle SOA Suite 11gでは、5種類のコンポーネントをSCAコンポジット内で使用することができます。
- BPEL Process: Business Process Execution Language (BPEL) はビジネスプロセスを定義するための言語です。このプロセスはXMLで定義され、主要な目的は機能サービスを統合することにあります。機能サービスとは、コンポジットの外部サービスもしくは同一コンポジットの別のコンポーネントです。BPELプロセスの主要な機能の一つは、同期統合、相関IDを使った非同期の統合が可能、というものです。BPELプロセスをコンポジット内で使用し、プロセスの形で業務ロジックを定義します。
- Oracle Business Rules: Oracle Business RulesコンポーネントはSCAコンポジット内のルールリポジトリとして機能します。その主要目的はアプリケーションコードの外でビジネスポリシーを定義する命令を定義することです。これらのルールを定義するための実装言語を技術者以外でも読みやすくすることができ、ルールエンジンを使うことでルールを実行時に変更できます。つまり再コンパイルやアプリケーションを停止しなくてすむのです。ルールはXMLで定義され、文章もしくはデシジョン表の形で導入します。
- Human Workflow Task: Human Workflow Taskコンポーネントを使うと、SCAコンポジット内でユーザとのやりとりが可能になります。事前定義済みのワークフローが数種類あり、複雑な手作業による介入を手助けしてくれます。通常はBPELプロセスと共に使い人やグループ、事前定義済みのロールが実行するタスクを定義します。認証時にユーザは、他のコンポーネントや他者が割り当てた、利用可能なタスクにアクセスすることができます。これらのタスクを事前定義済みのワークフローアプリケーションを使って閲覧することができます。もしくは、利用可能なJava APIを使ったカスタムアプリケーションからもアクセスできます。
- Mediator: メディエータがSCAコンポジット内のメッセージディスパッチャとして動作します。mediatorは、コンポジット内の他のコンポーネントとの統合に使います。着信メッセージに基づいて、メッセージをどのコンポーネントにルーティングすべきかを判断します。これとは別に、さまざまなメッセージをルーティングする前に、XSL変換(XSLT)を使用して変換することができるため、様々なコンポーネントを切り離し、各々固有の入出力メッセージを持たせることができるようになります。
- Spring Contexts: Spring BeanもSCAコンポジット内に含めることができます。これにより、Javaの機能を実行したり、以前に開発したJavaコンポーネントを再利用できるようになります。Springコンテキストコンポーネントは、ふつうのSpring構成ファイルに2つの新しいタグ(SCA-serviceとSCA-reference)を拡張しています。これらのタグにより、Spring Beanは、他のSCAコンポーネントのサービスを利用でき、他のSCAコンポーネントによって利用され得るサービスを公開することができます。
Oracle Metadata Services
MDSを、Oracle Fusion Middlewareの内部の中央リポジトリとして記述することができます。その主目的は、Oracle Fusion Middlewareのコンポーネントがメタデータを維持、管理、アクセスできる集中ストアを提供することです。
メタデータは、データに関するデータとして定義されることがよくあります。言い換えると、他の情報に意味を与え、記述する情報の断片として定義されます。 Oracle Fusion Middlewareコンポーネントが使用するメタデータの典型的な例は、中でもXMLファイル、XMLスキーマファイル、XSL変換、SCAコンポジット、BPELプロセス、WSDL、ビジネス·ルール、Oracle ADFページ、JaveServer Pages(JSP)、Oracle ADFタスク·フローです。これらのリソースは、構成パラメーターやデータ定義だけでなく、複雑なビジネスロジック、インタフェースコントラクト、およびビジネス·ルールをも含みます。したがって、特別な方法で管理することが重要であり、そうすれば、簡単に更新され、外部の世界と共有することができます。
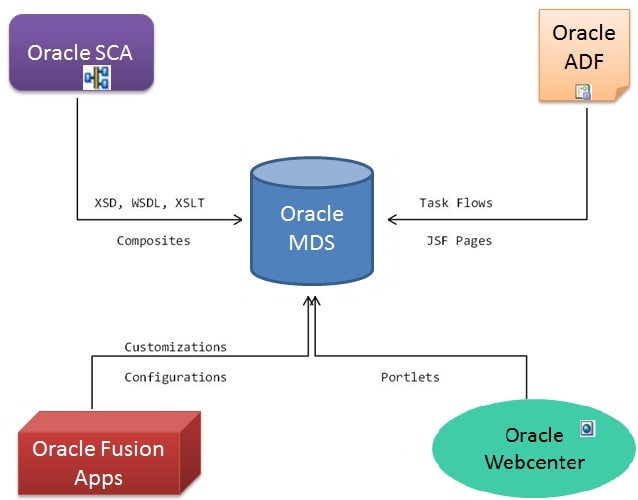
Oracle FormsアプリケーションやJava EEアプリケーションなど、一般的な2階層または3階層アプリケーションでは、ビジネス·データを、通常データベース内に格納して、管理やアクセスを容易にするために集約します。ビジネスコンポーネントは、情報の在処やアクセス方法がわかっているので、必要な情報を探し回る必要はありません。データを異なるアプリケーション間で共有でき、データの変更は、整合性が保証され、一点のみで行われる必要があります。 MDSは、Oracle Fusion Middlewareコンポーネントのメタデータのために同じ考え方を適用します。クラスパスやJARファイル、あるいはデータベース内にいくつかのメタデータリソースを持つのではなく、MDSでリソースを単一の場所で集中保持できます。図2は、Oracle Fusion MiddlewareコンポーネントのMDSとのやりとりです。
 |
| 図2 Oracle Fusion Middleware and MDS |
メタデータ·リポジトリを使用することは多くの正当性があります。まず、XMLファイルまたはXSDスキーマファイルなどのメタデータは、通常、異なるコンポーネント間で共有されます。したがって、すべてのコンポーネントがこれらのリソースに容易にアクセスし、参照できることが必要なだけでなく、一貫性を維持することも重要です。つまり、メタデータの変更は、それを参照しているすべてのコンポーネントに反映されるべきなのです。各メタデータリソースのコピーを1つだけ用意すれば、不要な冗長性を避け、変更が一箇所だけでなされることを保証します。
第二に、機能的なデータと同様に、メタデータにはライフサイクルがあります。つまり、例えば分析、設計、開発、テスト、生産などのさまざまなプロジェクトのフェーズを通して、メタデータの異なるバージョンが存在します。すべてのバージョンを管理する必要があり、フェーズに応じて、簡単に交換できなければなりません。あるバージョンから別のバージョンへの変更したり、以前のバージョンにロールバックしたりして、コンポーネントの整合性や振る舞いを台無しにしてはいけないのです。
第三に、機能的なデータと同様に、メタデータを管理する必要があります。一般的に必要な機能の中では、メタデータの追加、更新、削除、ラベリング、キャッシング、バージョン管理の機能です。1カ所に集中せず、いくつかの場所に格納されていた場合、これらのリソースを維持することは非常に難しいでしょう。
第四に、多くのコンポーネントは、このメタデータを使用するため、ボトルネックを回避し、単一障害点になることを避けるため、可用性と性能が高いことを要求されます。メタデータは、基本的な部分で考慮されるべきクラスタリング、レプリケーション、ロードバランシングなどの機能的なデータやコンセプトと同じ特別な取扱いを必要とします。
MDSリポジトリのいくつかの機能は、メタデータを扱うため非常に堅牢なソリューションになっています。それらを検討する前に、まずは2種類のリポジトリ(ファイルベースとデータベースベース)があり、以下でご説明する機能のほとんどはデータベースベースリポジトリにおいてのみ可能である、ということをお伝えしなければなりません。データベース·ベースのリポジトリは本番環境での利用を意図しているのに対し、ファイルベースのリポジトリは、開発環境のためのものです。
- Customized applications: この機能はどちらのリポジトリでも利用でき、通常はOracle ADFアプリケーションで使われます。カスタマイズされたアプリケーションはベースとなるアプリケーションや複数のカスタマイズ層上に構築されます。カスタマイズ層はMDSリポジトリに格納され、ベースアプリケーションと実行時にマージされます。
- Query optimization: データベースリポジトリは、データベースの機能を使ってコンテンツのクエリを最適化できます。いくつかの事前設定されたインデックスと、全体的なパフォーマンス向上に役立つパージ機構があります。また、実行時に変更されないメタデータを構成して、高速にアクセスするためキャッシュすることができます。 MDSはメタデータの変更を検知できるので、キャッシュを最新に保つことができます。
- MDS query API: このAPIはメタデータ属性、メタデータの値、メタデータの型、メタデータのパス、さらにはテキストの内容に基づくクエリーを定義する機能を提供します。
- Transaction support: データベース·ベースのMDSリポジトリは、データベースのトランザクションを使用して、リポジトリのインポートや更新に失敗した場合に、以前の状態にロールバックすることができます。
- Versioning: バージョン管理は、データベース·ベースのMDSリポジトリでのみ利用できます。メタデータを単に元のバージョンを上書きするのではなく、異なるバージョンを付けて保存することができます。バージョンは別に保存されており、バージョン履歴を構成し、特定の時点のメタデータを表示することができます。各バージョンにラベルを付けて、特定のバージョンを取得しやすくすることができます。
- Change isolation: メタデータへの変更を分離し、特定のクライアント向けにのみ適用することができるので、全ての利用者に変更をリリースするまえ にテストを実行することができます。この機能は、データベース·ベースのリポジトリでのみ利用可能です。
- Change detection: 前述のように、メタデータは異なるコンポーネント間で共有されると想定しています。この機能は、コンポーネントがメタデータの変更をポーリング(もしくは変更を購読)し、共有リソースが変更された際に検知でき、再起動することなく、新しいバージョンを使用することができる、というものです。この機能は、データベースベースのリポジトリでのみ有効です。
- Shared metadata repository: この機能は、異なるコンポーネント間のメタデータ·リポジトリを共有するものです。共有メタデータリポジトリは、すべてのメタデータを集中管理し、各利用者向けに最新に維持管理します。この結果再利用を促進し、不必要な重複を回避します。変更検知を利用する場合には共有メタデータリポジトリが必要です。
- Partitions: MDSリポジトリでは、各コンポーネントとアプリケーションは、独自のパーティションを持っています。パーティションを使うとデプロイメントが相互に独立した状態を維持することができます。言い換えれば、パーティションはMDSリポジトリ内の論理的な独立したリポジトリで、一つ以上のアプリケーションと関連づけることができます。この機能は、ファイルベースとデータベース·ベースのリポジトリで利用できます。
- Label: 各パーティションには、複数のラベルを付けることができます。各ラベルは、パーティション内のメタデータの状態(スナップショット)を表します。図3は、MDS内のラベルを示しています。
 |
| 図3 MDS Labels and Partitions |
- Namespaces: MDSリポジトリ内部の名前空間は、リポジトリ内のメタデータのホームパスを定義しています。実行時には、3個の事前定義済みの名前空間(apps、deployed-composites、soa-shared)を使用します。名前空間は、メタデータの場所を指定するためにadf-config.xml ファイル内で利用されます。カスタムXMLファイルを通常名前空間apps内部に配置しますが、コンポジットは名前空間deployed-compositesの中に格納します。標準のSOAアーティファクトは名前空間soa-shared(/soa/shared)の中に格納されています。
MDSリポジトリの管理
既述の通り、MDSリポジトリとして、ファイルベースまたはデータベースベースのリポジトリを使用できます。ファイルベースのリポジトリの意図は、開発者が簡単に開発およびテストで使えるよう、ローカル環境で利用可能な軽量なリポジトリを用意することです。ファイルベースのリポジトリは、ファイル参照やカスタマイズといった必要な機能は提供しつつ、開発者が外部データベースの維持管理や構成をしなくてすみます。OS内のディレクトリ構造に類似のディレクトリ構造を定義できるので、これらのリポジトリを簡単に変更したり管理することができます。共通のシェルコマンドやGUIのFile Explorerアプリケーションの類を利用してリポジトリ内を遷移し、変更することができます。ファイルベースのリポジトリは、デフォルト構成を使用している場合、通常はOracle JDeveloperホーム(JDEV_HOME/integration)内にありますが、adf-config.xml構成ファイル内で各アプリケーション用に外部ディレクトリを構成することもできます。
対して、データベースベースのリポジトリは、堅牢性が必要とされる本番環境で使用されています。これらのリポジトリは、Oracleから提供されるリポジトリ作成ユーティリティ(RCU)アプリケーションを使って作成します。このユーティリティは、データベーススキーマと、それに対応する表やオブジェクトを作成するのに役立ちます。リポジトリは、後からOracle Enterprise Manager Fusion Middleware Controlのコンソールで登録したり登録解除したりすることができます。図4は、コンソールでのリポジトリ表示の例です。
 |
| 図4 MDS Repositories in the Oracle Enterprise Manager Fusion Middleware Control Console |
ディレクトリ構造も、Oracle JDeveloperを使って遷移したり調査することができます。単一のファイルをOracle JDeveloperで閲覧することができますが、重要なことは、WLSTコマンドを使ったり、新たにファイルこデプロイする以外にはファイルやディレクトリ構成を変更できない、つまりOracle JDeveloperでは変更できない、ということです。
次のセクションでは、データベースベースのMDSリポジトリ向けの基本的な管理コマンドを公開しています。ファイルリポジトリは直接編集できるので、これらのコマンドはファイルベースのリポジトリでは利用できません。
管理
リポジトリの作成と登録
前の章で説明した通り、データベースベースのリポジトリの場合、RCUユーティリティを使って作成する必要があります。MDSリポジトリはOracle SOA Suiteのような製品の前提条件になっているため、そうした製品のためのスキーマを作成した際に自動的にリポジトリを作成します。とは言っても、新たに独立したリポジトリをRCUを使っていつでも作成することができます。新しいリポジトリはOracle Enterprise Manager Fusion Middleware ControlのコンソールもしくはWLSTコマンドを使って登録する必要があり、その上で全ての管理対象サーバもしくは特定の管理対象サーバがリポジトリにアクセスできるようになります。
ファイルの追加
WLSTコマンドの利用もしくはJAR(Javaアーカイブ)、MAR(メタデータ・アーカイブ)をデプロイしてMDSにファイルを追加・更新することができます。Oracle Commonホーム(<MW_HOME>/oracle_common)のWLSTスクリプトではMDSにファイルを追加したり更新するための
importMetadataコマンドを提供しています。このコマンドを使うと、ドキュメントの完全修飾ドキュメント名やドキュメント名のパターンを使って1個以上のファイルを追加できます。就職使ってことができます。ファイルを追加します ファイルが存在しない場合は追加、リポジトリにファイルが存在している場合は上書きします。特定のラベルにファイルを追加したり、アップロード前にバージョン付けすることができます。
SCAとMDSのセクションで
importMetadataコマンドの例を示しています。
Antスクリプト、Oracle JDeveloper、WLSTコマンドのうち1つを使って、メタデータファイルをリポジトリにデプロイすることも出来ます。デプロイプロセスはSCAコンポジットのデプロイプロセスと似ており、実は利用できるAntスクリプトは全く同じです。メタデータファイルのデプロイの第1段階は、JAR(もしくはMAR)ファイル内に所定の構造でファイルを格納することです。ファイルを格納するディレクトリ構造はリポジトリで使ったディレクトリ構造と同一です。そのため、ファイルがディレクトリを持たない場合、直接リポジトリ中のアプリケーションのディレクトリに入れることになります。JARファイルがMdsApp/schemasディレクトリ内にファイルを持つ場合、apps/MdsApp/schemasディレクトリを作成し、ファイルをその中に格納します。MARファイルは通常Oracle ADFアプリケーションがメタデータを格納するために使います。SOA Suiteの世界では、メタデータは通常JARファイルの形でパッケージ化します。
JARファイルを作成したら、SCAバンドルを作成し、JARファイルをその中に格納する必要があります。その上で、このSCAバンドルをMDSリポジトリにデプロイすることができます。AntスクリプトもしくはOracle JDeveloperを使ってメタデータファイルをパッケージ化できます。Antを使うと、zipのターゲットをJARファイルやSCAバンドルファイルを構築するために使います。その後、
ant-sca-deploy.xmlファイルからデプロイターゲットを参照してSCAバンドルをデプロイします。
Oracle JDeveloperを使う場合、2個のデプロイメントプロファイルを定義する必要があります。JARファイルは最初のデプロイメントプロファイルで作成され、プロジェクトレベルで定義します。SOAバンドルは2個目のデプロイメントプロファイルで先ほど生成されたJARファイルに含まれなければなりません。このデプロイメントプロファイルはアプリケーションレベルで定義する必要があります。SCAバンドル(もしくはSOAバンドル)を直接Oracle JDeveloperにてant-sca-deploy.xmlファイルを使って、もしくはOracle Enterprise Manager Fusion Middleware Controlのコンソールからデプロイできます。Antタグをラップし、MDSファイルのデプロイのためのわかりやすいタグを定義するAntスクリプトのサンプルもいくつかあります。
ファイルの更新
ファイルを直接更新できません。ファイルを変更するには、エクスポートして上書きするか、再デプロイする必要があります。ファイルを直接Oracle JDeveloperから閲覧することはdけいますが、編集することはできません。一つの方法として、WLSTから
exportMetadataコマンドを使ってファイルをダウンロードし、変更した上で、WLSTから
importMetadataコマンドを使ってアップロードするやり方があります。
ファイルの削除、パージ
特定のファイルまたはディレクトリ全体構造をdeleteMetadata WLSTコマンドを使って削除することができます。
exportMetadataや
importMetadataと同様に、完全修飾された文書名や文書名のパターンを定義することができます。アプリケーションのバージョンは省略可能です。バージョンが省略されている場合、最新バージョンが削除されます。
ラベルがついていない文書をパージできます。これは
purgeMetadataと呼ばれるWLSTコマンドを使用して行います。このコマンドで指定された値よりも古く、ラベル付けされていないバージョンがデータベースからパージされます。
Java API
Oracle SOA A-TeamがMDSリポジトリへのアクセスや修正もできるJavaクラスを作成しました。これはOracle JDeveloperで使用される機能に基づいています。MDSUtils.javaと呼ばれるこのJavaクラスは、フォルダの作成および削除、リポジトリ内のリソースの検索もできます。さらに、このJavaクラスは、WLSTでアクセスできます。 詳細は以下のエントリからどうぞ。
Full access to MDS Repository (SOA A-Team blog)
https://blogs.oracle.com/ateamsoab2b/entry/full_access_to_mds_repository
https://blogs.oracle.com/ateamsoab2b/
MDS MBeans
MDSリポジトリは、メタデータの管理とリポジトリ自体の管理を可能にする2種類のMBeans(manage beans)を提供しています。どちらのMBeanも、
oracle.mds.lcmパッケージ内の"Application defined MBeans"(アプリケーション定義済みのMBean)カテゴリの下に置かれます。
MDSDomainRuntime MBeanは、リポジトリを管理するためのオペレーションを提供します。このMBeanを使用すると、いくつかある機能のうち、特にパーティションのリスト表示、リポジトリのリスト表示、パーティションの作成、ラベルの作成、リポジトリの登録、パーティションの削除、を一覧表示することが可能です。
MDSAppRuntime MBeanはメタデータファイルを変更する機能を提供します。MDSリポジトリを使うアプリケーション毎に
MDSAppRuntime MBeanがあります。例えば、soa-infra用、composer用、
wsm-pm用のMBeanがあります。リポジトリを使う任意のOracle ADFアプリケーションもまたMBeanを取得します。対して、SCAコンポジットは
soa-infraアプリケーション内で実行するため、
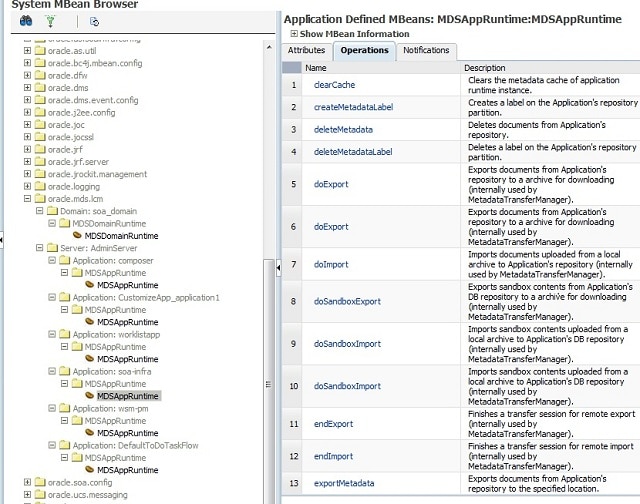
soa-infraアプリケーションと同じMBeanを使います。これらのMBeansはメタデータの削除、パージ、エクスポート、インポートといった機能を提供します。図5では、Oracle Enterprise Manager Fusion Middleware Controlのコンソール内のMDS MBeanブラウザの表示例です。
 |
| 図5 MDS MBean Navigator |
Oracle JDeveloper内のMDS
Oracle JDeveloperはOracle Fusion Middlewareコンポーネントやアプリケーションを開発するための主要なIDE(Integrated Development Environment/統合開発環境)です。Oracle JDeveloperを使うと、メタデータを格納するMDSリポジトリを参照することができます。この機能のおかげで、開発されたコンポーネントはメタデータの物理位置に依存しせず、簡単に異なる環境にデプロイできます。その際も対応するメタデータ参照を再構成する必要はありません。この機能を使うと、開発者は他の環境(テスト環境、本番環境など)をシミュレートするローカルの開発環境を持つことができます。メタデータリポジトリへの参照を
adf-config.xmlファイルに定義します。
先ほど述べたように、Oracle JDeveloperではグラフィカルに様々なMDSリポジトリをナビゲートすることもできます。(ファイルベースでもデータベースベースの)リポジトリにアクセスするには、接続を定義する必要があります。その後、ツリー構造をOracle JDeveloper内で閲覧することができ、
ファイルの更新 の段で説明したオプションを使って、メタデータを編集することができます。
Connections
Oracle JDeveloperでMDSリポジトリの接続を定義するためには1個もしくは2個の手順を踏む必要があります。これはアクセスするリポジトリの種類によって変わります。ファイルベースのリポジトリへの接続を作成する場合、MDSリポジトリのルートパスのみ指定すればよいのです。このルートパスは通常Oracle JDeveloperのホームパス内(
JDEV_HOME/integration/apps)にあります。初めての場合、appsディレクトリを手作業で
integrationディレクトリ内に作成する必要がありますが、
adf-config.xmlファイル内で設定することができます。
データベースベースのリポジトリ接続を作成するためには、まず
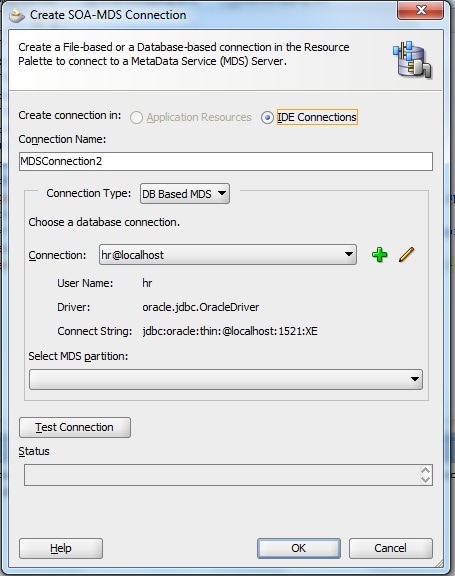
mds-schemaにポイントするそれぞれのデータベース接続を定義する必要があります。その後、MDS接続をデータベース接続に基づいて作成することができます。図6はOracle JDeveloperの接続ウィザードです。
 |
| 図6 Connection Wizard |
The adf-config.xml
adf-configファイルは当初Oracle ADFアプリケーションでのみ使われてた設定ファイルですが、現在ではOracle SOA SuiteやOracle WebCenterなどのOracle Fusion Middlewareコンポーネントでも使われています。このファイルは以下のOracle ADFアプリケーションレベルの設定を含んでいます。
- メタデータの検証
- リソースバンドルのキャッシュ
- タスクフローの設定
- 暗黙的なセーブポイント
- Oracle ADFビジネスコンポーネントのグローバル設定
- Oracle ADFセキュリティ
- シード・カスタマイズ
- ユーザ・カスタマイズ
- 変更永続性
- MDSリポジトリ
こうした設定は通常デプロイ時や実行時に変更します。これらの設定に関する詳細は、以下のドキュメントをご覧下さい。
Oracle® Fusion Middleware Fusion Developer's Guide for Oracle Application Development Framework 11g Release 1 (11.1.1)
http://docs.oracle.com/cd/E15523_01/web.1111/b31974/title.htm
Oracle® Fusion Middleware Oracle Application Development Framework Fusion開発者ガイド 11gリリース1(11.1.1.6.0)
http://docs.oracle.com/cd/E28389_01/web.1111/b52028/title.htm
SCAアプリケーション用に、Oracle JDeveloperは.adf/META-INFディレクトリ内に
adf-config.xmlファイルも作成します。この
adf-config.xmlファイルを使って、設計時に参照できるいくつかのMDSリポジトリを構成することができます。Oracle JDeveloperはこうした参照を使ってコンポジットを検証し、コンパイルします。以下の例はリポジトリがどのように参照されているかを示しています。
<?xml version="1.0" encoding="windows-1252" ?>
<adf-config xmlns="http://xmlns.oracle.com/adf/config"
xmlns:config="http://xmlns.oracle.com/bc4j/configuration"
xmlns:adf="http://xmlns.oracle.com/adf/config/properties"
xmlns:sec="http://xmlns.oracle.com/adf/security/config">
<adf-adfm-config xmlns="http://xmlns.oracle.com/adfm/config">
<defaults useBindVarsForViewCriteriaLiterals="true"/>
<startup>
<amconfig-overrides>
<config:Database jbo.locking.mode="optimistic"/>
</amconfig-overrides>
</startup>
</adf-adfm-config>
<adf:adf-properties-child xmlns="http://xmlns.oracle.com/adf/config/properties">
<adf-property name="adfAppUID" value="MdsApp3.demo.wpmds"/>
</adf:adf-properties-child>
<sec:adf-security-child xmlns="http://xmlns.oracle.com/adf/security/config">
<CredentialStoreContext credentialStoreClass="oracle.adf.share.security.providers.jps.CSFCredentialStore"
credentialStoreLocation="../../src/META-INF/jps-config.xml"/>
</sec:adf-security-child>
<adf-mds-config xmlns="http://xmlns.oracle.com/adf/mds/config">
<mds-config xmlns="http://xmlns.oracle.com/mds/config">
<persistence-config>
<metadata-namespaces>
<namespace metadata-store-usage="mstore-usage_1" path="/soa/shared"/>
<namespace metadata-store-usage="mstore-usage_2" path="/apps/WPMDSDemo2"/>
<namespace metadata-store-usage="mstore-usage_2" path="/apps/WPMDSDemo3"/>
</metadata-namespaces>
<metadata-store-usages>
<metadata-store-usage id="mstore-usage_1">
<metadata-store class-name="oracle.mds.persistence.stores.file.FileMetadataStore">
<property value="${oracle.home}/integration" name="metadata-path"/>
<property value="seed" name="partition-name"/>
</metadata-store>
</metadata-store-usage>
<metadata-store-usage id="mstore-usage_2">
<metadata-store class-name="oracle.mds.persistence.stores.db.DBMetadataStore">
<property value="DEV1_MDS" name="jdbc-userid"/>
<property value="jdbc:oracle:thin:@localhost:1521:XE" name="jdbc-url"/>
<property value="soa-infra" name="partition-name"/>
</metadata-store>
</metadata-store-usage>
</metadata-store-usages>
</persistence-config>
</mds-config>
</adf-mds-config>
</adf-config>
異なるMDSリポジトリを<persistence-config>タグ内で定義します。MDSリポジトリの構成は2個の部分から構成されています。一つは名前空間、一つはメタデータストアです。
名前空間はリポジトリ内のメタデータのホームパスを定義します。実行時にはOracle MDSリポジトリが以下の3個の事前定義済み名前空間を定義します。
apps: カスタムアーティファクトを格納するために予約されている名前空間deployed-composites: SCAコンポジットを格納するための名前空間/soa/shared: 標準のSOA Suiteアーティファクトのために予約されている名前空間
namespace タグで定義されているホームパスはOracle JDeveloperがメタデータを探索する起点として利用します。異なる複数のメタデータのホームパスを同一名で定義して、コンポジットが同一ストア内パスを参照できます。
もう一つのパートはリポジトリそのものの構成です。リポジトリは
metadata-store-usageタグ内で定義されます。このタグには先ほど
namespaceタグで定義した
metadata-store-usageに対応する参照も含んでいます。ファイルベースのリポジトリでは
oracle.mds.persistence.stores.file.FileMetadataStoreクラスを使い、メタデータを物理的に格納する場所を指定するメタデータパスを指定する必要があります。
管理の章で述べたように、このパスは通常Oracle JDeveloperのホームディレクトリ内にありますが、OSの環境変数を使いカスタムディレクトリを定義することもできます。そのため、
${oracle.home}/integrationの下のメタデータの代わりに、ユーザは$
{MDS.HOME}/filesディレクトリをメタデータのルートパスとして定義できます(
MDS.HOMEをこの作業のために環境変数として定義する必要があります)。データベースベースのリポジトリでは
oracle.mds.persistence.stores.db.DBMetadataStoreクラスを使い、プロパティを定義してデータベース接続を確立する必要があります。
この章の最初に挙げた例で、2個のリポジトリを定義しました。一つ目はファイルベースのリポジトリで、ルートパスは
${oracle.home}/integrationでした。このリポジトリは/soa/sharedをホームパスとして定義している
mstore-usage_1を参照しています。言い換えれば、Oracle JDeveloperはメタデータを
${oracle.home}/integration/soa/sharedというパスで探索します。環境変数を使って、上述の通り、
${oracle.home}とは異なる場所を指定することができます。例えば、
${MDS.HOME}/integration/soa/sharedもしくは
${metadata.dir}/integration/soa/sharedといった具合です。
もう一つはデータベースリポジトリで、
mstore-usage_2を参照しています。
mstore-usage_2が2度定義されているため、Oracle JDeveloperはSCAコンポジットで参照しているメタデータを探索するためのホームパスとして、両方のパス(
/apps/WPMDSDemo2と
/apps/WPMDSDemo3)を使います。
SCAとMDS
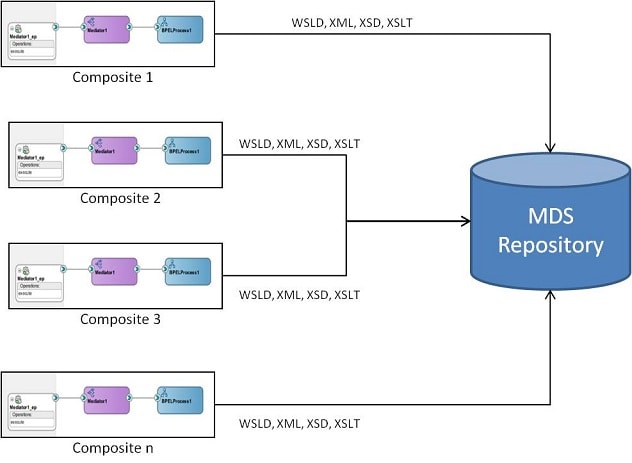
これまでのコンセプトを全て公開してやっと、ローカルでメタデータを持たずに外部リポジトリからメタデータを参照するSCAコンポジットを開発する方法を説明することができます。このアプローチを使う主な理由は、コンポーネントのインターフェース定義をその実装から分離することを指示する開発のベストプラクティスに従うことです。図7は、このアプローチを示しています。
 |
| 図7 SCA Composites and MDS |
開発時のメタデータ
たいていの場合はSCAコンポジットの開発時にはローカルファイルリポジトリを使うことを推奨しています。この構成により、開発者は他の開発者に影響せずにローカルの変更をすることが可能になります。その後、SCAコンポジットやメタデータをデータベースベースの集中管理されているMDSリポジトリがインストールされているテスト環境にデプロイできます。
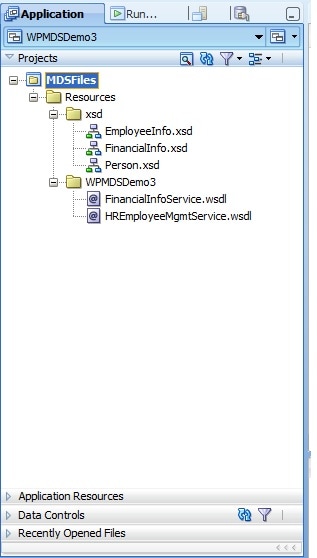
SCAコンポジットをその定義から分離するために、Oracle JDeveloperで少なくとも2個の独立したアプリケーションを持つことを推奨します。一つはメタデータのアプリケーション、もう一つは異なるコンポジットのためのアプリケーションです。出発点は、メタデータ·アプリケーションである必要があります。メタデータファイルも前述のWSLTコマンドを使用してデプロイできますので、メタデータ·アプリケーションは、必須ではありませんが、XMLビジュアルデザインビューと履歴レビューなどの追加のOracle JDeveloperの機能を活用するためにメタデータのプロジェクトを持っているほうがいいでしょう。メタデータ·アプリケーションは、ファイルを対応するフォルダ構造に保存する1つの汎用プロジェクトを含みます。異なるコンポジット間で共有するすべてのXSD、XSLT、WSDL、およびXMLのアーティファクトは、このプロジェクトに存在する必要があります。図8は、サンプルのMDSプロジェクトを示しています。
 |
| 図8 MDS Project |
プロジェクトを作成したら、WSLTコマンドまたはSCA Antスクリプトまたは直接Oracle JDeveloperを使ってデプロイできます。これらのアプローチは、次のセクションで詳細に説明します。
SCAコンポジットは、MDSリポジトリ内のメタデータへの参照を使用して開発されるべきです。通常、コンポジット定義ファイル、メディエータ、BPELプロセス、およびその他のコンポーネントは、ローカルファイルシステムまたは対応するURLを使用してリモートサーバから、他のメタデータファイルを参照します。MDSリポジトリ内のファイルにはリソースアクセスに利用可能なURLがあり、以下のようになっています。
oramds:/apps/directory1/directory2/someFile.wsdl
oramdsというプレースホルダはリソースがMDSリポジトリ内に存在することを示すために使われます。Oracle JDeveloperはadf-config.xmlを探して構成されたリポジトリからリソースを探索します。Oracle SOA Suiteはoramdsキーワードを解釈し、インストールで構成されたリポジトリ内のリソースを探します。メタデータが格納されている標準のパスはappsです。Oracle JDeveloperやSCA Antスクリプトでデプロイする場合、メタデータ構造の全体をappディレクトリに格納します。他のディレクトリやファイルはメタデータプロジェクト自体によって変わります。
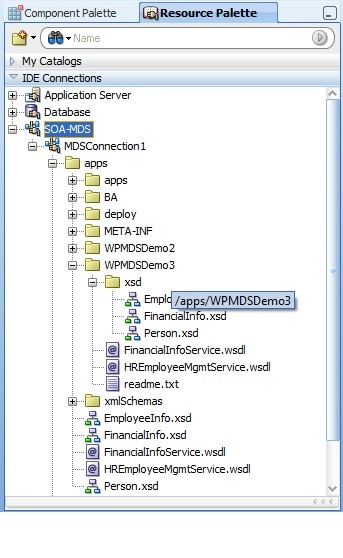
Oracle JDeveloperは、リソースを探索したり含めることができるナビゲータ画面を提供しているので、SCAコンポジットのアーティファクトにMDSのURLを含めることが簡単になっています。このナビゲータ画面はIDE接続の中のMDS接続を選択し、SOAリソース·ブラウザから利用できます。MDS接続はリポジトリをナビゲートできる、ということがポイントです。図9は、MDSナビゲータ画面の様子です。
 |
| 図9 MDS Navigator in Oracle JDeveloper |
リソースを選択した後、Oracle JDeveloperは
oramds:/apps/...の形でURLを生成します。
ファイルが変更されないので、XML、XSLT、XSDをローカルファイルやリモートサーバでなくMDSリポジトリから含めることが簡単でしょう。WSDLファイルの場合、エンドポイントアドレスの問題があります。エンドポイントアドレスはデプロイに特有の情報であるのに対し、WSDLファイルは汎用的なリソースであるため、MDSリポジトリ内に格納されているWSDLファイルは、エンドポイントアドレスを保持しないようにすべきでです。SCAコンポジットのうちWSDLを参照としてインポートするものはエンドポイントアドレスを
composite.xmlファイルに定義することができます。このプロパティは構成プランや実行時にOracle Enterprise Manager Fusion Middleware Controlのコンソールから変更できます。このように参照のバインディング内のエンドポイントプロパティを定義することにより実現できます。
<binding.ws port="http://xmlns.oracle.com/bpel/workflow/taskService#wsdl.en
dpoint(TaskService/TaskServicePortSAML)"
location="http://localhost:7001/integration/services/TaskService/
TaskServicePortSAML?ORAWSDL"
soapVersion="1.1">
<property name="weblogic.wsee.wsat.transaction.flowOption"
type="xs:string" many="false">WSDLDriven</property>
<property name="endpointURI"
type="xs:string">http://localhost:7001/integration/services/TaskService/
TaskServicePort</property>
</binding.ws>
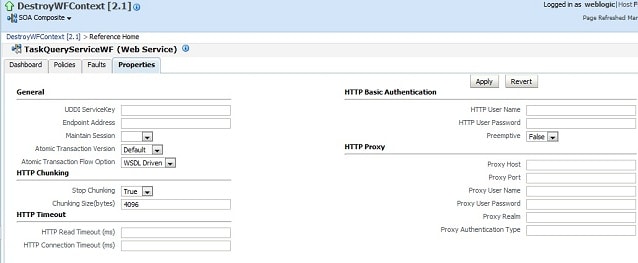
このプロパティを後で実行時にOracle Enterprise Manager Fusion Middleware Controlの[サービス]/[プロパティの参照]メニューから変更できます。図10はコンソールの例です。
 |
| 図10 Endpoints in the Oracle Enterprise Manager Fusion Middleware Control Console |
SCAとMDSのデプロイ
メタデータプロジェクトをまずデプロイするのは、SCAコンポジットがメタデータに依存していて、そのままではSCAコンポジットをデプロイできないためです。先ほど述べた通り、メタデータのデプロイには3つの方法(WLSTコマンドの利用、Antスクリプトの利用、Oracle JDeveloperの利用)があります。
WLST Commands
MDSファイルのデプロイ用に2個の異なるWLSTコマンド、
importMetadataと
sca_deployCompositeがあります。 どのコマンドを使う場合でも、Oracle SOA Suiiteのインストール環境(通常
SOA_HOME/common/bin)からWLSTツールを使ってコマンドを実行します。また、
importMetadataコマンドはオンラインで実行する必要があるため、最初に
connect()する必要があります。
importMetadataコマンドを使い、一つ以上のファイルをワイルドカードを使ってリポジトリにデプロイできます。このコマンドに3個の必須パラメータがあります。
- 最初のパラメータは、メタデータをOracle SOA Suiteにデプロイし参照するため、対応する値としてアプリケーション名(
soa-infra)を使う
- 次のパラメータはサーバ名で、Oracle SOA Suiteがインストールされている管理対象サーバ名
- 3個目のパラメータはドキュメント転送対象のソースディレクトリ。このパラメータをdocsパラメータ(省略可能)と共に使うと、転送対象のファイルをフィルタリングすることができる。このパラメータではワイルドカード(*や**)が利用でき、所望のファイルをフィルタリングすることができる。このパラメータは指定された構造全てをインポートすることに注意すること。そのため、
docs='/apps/directory1/*.txt'をパラメータとして指定した場合、txtで終わる全てのファイルがリポジトリの/apps/directory1に転送される。
以下は
importMetadataコマンドの利用例です。
importMetadata(application='soa-infra', server='AdminServer',fromLocation='D:\mywork\WPMDSDemo\MDSFiles',
docs='/apps/WPMDSDemo3/**')
このコマンドは
D:\mywork\WPMDSDemo\MDSFiles\apps\WPMDSDemo3 のファイルを全てリポジトリの
/apps/WPMDSDemo3 ディレクトリに移送します。このコマンドの詳細はOracle Fusion Middleware WebLogic Scripting Tool Command Referenceをご覧下さい。
Oracle® Fusion Middleware WebLogic Scripting Tool Command Reference 11g Release 1 (10.3.6)
http://docs.oracle.com/cd/E23943_01/web.1111/e13813/toc.htm
sca_deployCompositeコマンドはコンポジットを実際にデプロイするためのコマンドですが、メタデータファイルのデプロイにも利用できます。
importMetadataはより汎用的で他のテクノロジー(Oracle ADFなど)でも利用可能であるのに対し、
sca_deployCompositeは特にSCAコンポジット向けに開発されているため、このコマンドは使いやすいのです。このコマンドは単一ファイルをデプロイしませんので、全メタデータファイルを一つのJARファイルやSOAバンドルにまとめル必要があります。
sca_deployCompositeコマンドには、ターゲットサーバのURL(Oracle SOA Suiteがインストールされている管理対象サーバ)と、SOAバンドルもしくはJARファイルの場所という、2個のパラメータが必要です。以下はコマンドの利用サンプルです。
sca_deployComposite("http://localhost:7001","D:\mywork\WPMDSDemo
\MDSFiles\deploy\mds.jar")
このコマンドに関する詳細は、Oracle Fusion Middleware WebLogic Scripting Tool Command Referenceをご覧下さい。
Oracle® Fusion Middleware WebLogic Scripting Tool Command Reference 11g Release 1 (10.3.6)
http://docs.oracle.com/cd/E23943_01/web.1111/e13813/toc.htm
Ant Script
Oracle JDeveloperには、SCAコンポジットの管理を賄う数種類のAntスクリプトが同梱されています。
ant-sca-deploy.xmlスクリプトを使うと、コンポジットやメタデータファイルのデプロイが可能です。WLSTの
sca_deployCompositeコマンドを使う場合と同様、メタデータファイルをJARファイルもしくはSOAバンドルに事前にパッケージ化しておく必要があります。
以下は
ant-sca-deploy.xmlスクリプトを使ってメタデータファイルをデプロイするサンプルです。
ant -f ant-sca-deploy.xml -DserverURL=http://localhost:7001
-DsarLocation= D:\mywork\WPMDSDemo\MDSFiles\deploy\mds.jar)
詳細は以下のドキュメントをどうぞ。
Oracle® Fusion Middleware Developer's Guide for Oracle SOA Suite 11g Release 1 (11.1.1.6.3)
http://docs.oracle.com/cd/E23943_01/dev.1111/e10224/title_soase.htm
Oracle® Fusion Middleware Oracle SOA Suite開発者ガイド 11g リリース1 (11.1.1.6.2)
http://docs.oracle.com/cd/E28389_01/dev.1111/b56238/title_soase.htm
Oracle JDeveloper
他のテクノロジーと同様、JDeveloperはあーティファクトをリモートサーバにデプロイする機能を提供します。メタデータファイルのデプロイは主要な2ステップからなります。第1段階はメタデータプロジェクトをJARファイルにデプロイし、その後、soa-bundleをアプリケーションレベルで作成します。soa-bundleのデプロイメントプロファイルは先ほど作成したJARファイルを含む必要があります。JDeveloperを使ってデプロイする方法に関する詳細は、以下のドキュメントをご覧下さい。
Oracle® Fusion Middleware Developer's Guide for Oracle SOA Suite 11g Release 1 (11.1.1.6.3)
http://docs.oracle.com/cd/E23943_01/dev.1111/e10224/title_soase.htm
Oracle® Fusion Middleware Oracle SOA Suite開発者ガイド 11g リリース1 (11.1.1.6.2)
http://docs.oracle.com/cd/E28389_01/dev.1111/b56238/title_soase.htm
メタデータファイルをMDSリポジトリにデプロイした後にコンポジットを通常通り特段の変更なくデプロイすることができます。
まとめ
メタデータは全てのSCA開発で重要な部分で、インターフェース、参照されるサービス、データ構造、メッセージ、これらのメッセージの変換を定義しています。これらのメタデータファイルの一部を一つのSCAコンポジット内で使用したり、複数のSCAコンポジット内で使用したりする場合があります、特にWSDLファイルの場合、メタデータをコンポジット間で共有する必要があります。
共有メタデータファイルを集中管理されたリポジトリに格納すると、以下の利点があります。
- Consistency: 全てのコンポーネントは同一バージョンのメタデータを参照し、重複データの結果生まれる不整合がなくなります。
- Ease of maintenance: メタデータは1カ所のみで維持管理されなければなりません。
- Ease of change: メタデータの変更は参照する全てのコンポジットに反映されます。
- Reuse of metadata: 全てのメタデータを一つの集中管理したリポジトリで保持することにより、以前定義した構成の再利用を強制します。
以下の理由により、MDSリポジトリは集中管理したリポジトリにメタデータを格納する最善の選択しです。
- Oracle SOA Suiteネイティブで、実際に、Oracle SOA Suiteがコンポジットをデプロイする際に自動的に利用する
- Oracle JDeveloperは、SCAコンポジットを開発する上でMDSリポジトリの使用をサポートしている
- ファイルベースとデータベース·ベースのリポジトリは両方とも、(開発や本番といった)異なる環境でサポートしている
- SCAコンポジットは、使用されているリポジトリの種類とその位置から独立しています。コンポジットのデプロイプロセスはメタデータ·ファイルがローカルに格納されている場合と同様。
- パーティショニングやバージョニング、変更検知などの追加機能が提供されている
- MDSリポジトリをOracle JDeveloperからグラフィカルに遷移できる
- Oracle Enterprise Manager Fusion Middleware ControlからMDSリポジトリを簡単に設定できる
集中管理したメタデータリポジトリの利用は、そのメタデータを共有するコンポジットに適しています。 MDSリポジトリは、こうした要求に応えるだけでなく、エンドソリューションに堅牢性を追加するという付加機能を提供します。
参考資料