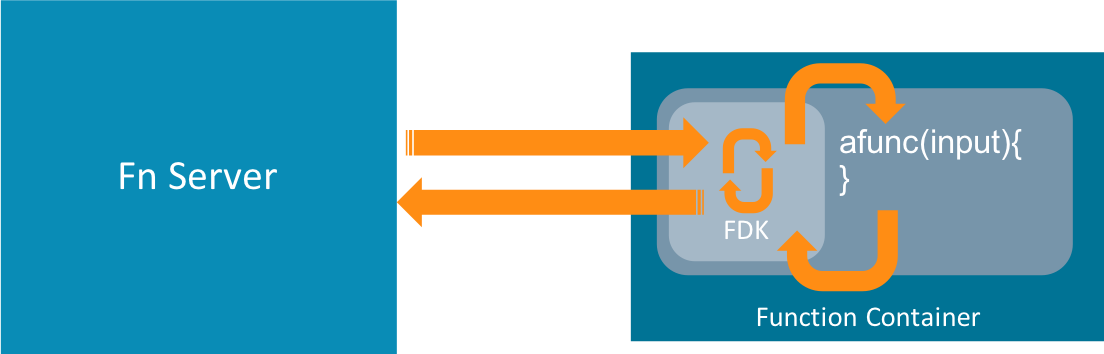
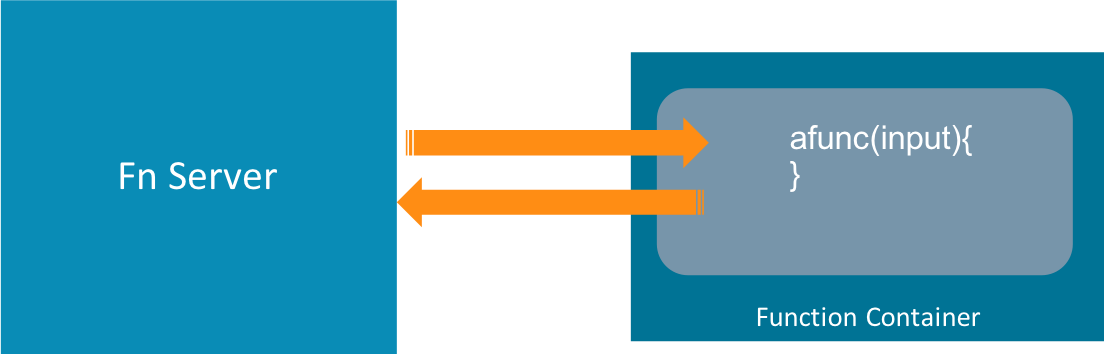
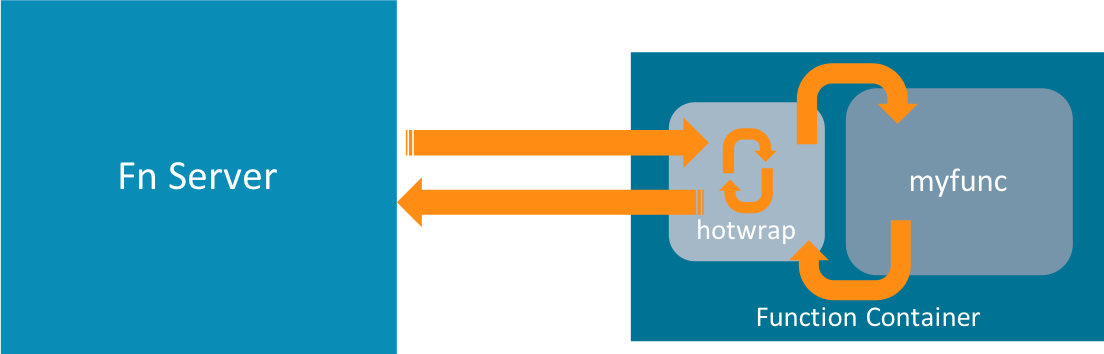
原文はこちら。
https://blogs.oracle.com/developers/microservices-from-dev-to-deploy-part-1-getting-started-with-helidon
マイクロサービスは間違いなく普及しています。アプリケーションを構築するためのマイクロサービスのアプローチ(または「マイクロサービスのアプローチを使うべき理由」)を使う利点を説明するエントリが多数あります。
Getting Started with Microservices, Part 1: Advantages and Considerations
http://blogs.oracle.com/developers/getting-started-with-microservices-part-one
Getting Started with Microservices, Part 2: Containers and Microservices
http://blogs.oracle.com/developers/getting-started-with-microservices-part-two
Getting Started with Microservices, Part 3: Basic Patterns and Best Practices
http://blogs.oracle.com/developers/getting-started-with-microservices-part-three
Getting Started with Microservices, Part 4: Fundamentals of DevOps with Containerized Microservices
https://blogs.oracle.com/developers/getting-started-with-microservices-part-four
その理由はたくさんありますが、チームが言語/フレームワークを自由に選択しつつ、独立したデプロイメント、スケーラビリティ、およびビルド時間とテスト時間の異なるサービスを実装できるという柔軟性は、とりわけマイクロサービスアプローチが今日の多くの開発チームにとって望ましいものである多くの要因の1つです。調査の結果、約86%の回答者がマイクロサービスのアプローチが今後5年間でデフォルトのアーキテクチャになると信じていることから、これ以上の議論は不要でしょう。
New study shows rapid growth in microservices adoption among enterprises
https://siliconangle.com/2018/05/02/new-study-shows-rapid-growth-microservices-adoption-among-enterprises/
前述の通り、「マイクロサービスでなければならない理由(Why microservices)」への回答はこれまでにあったので、この短いエントリでは、あなたの組織でマイクロサービスを実装する方法についての質問に答えてまいります。具体的には、お客様の開発チームがメンテナンス可能で拡張性の高い、簡単にテスト、開発、デプロイできるマイクロサービスアプリケーションのソリューションをOracleのテクノロジーがご支援できる点を紹介します。
話を面白くするため、このエントリのための架空のシナリオを思いつきました。
TechCorpという名前のスタートアップ企業が、素晴らしいプロジェクトのために開業資金として1億5000万USDを確保したとしましょう。
TechCorpの創業者であるLydiaは非常にノスタルジックで、56kモデムがピーガー言って"interwebs"へとつながった古き良き日を懐かしく思っており、パーソナライズされたホームページが大きく復活すると
BigCity Venture Capitalを納得させてきました。天気、金融情報、ニュース、それだけでなく、あなたの一日を明るくするインスパイアさせる言葉や面白い猫の写真…があったのを覚えていますよね?そこでLydiaは資金を確保し、世界中にイケてる開発者のチームを持つ多国籍企業をつくることになりました。LydiaとCTOのRajはマイクロサービスについて熟知しており、チームを分割してバックエンドの個々のパートに携わってもらい、マイクロサービスの強みを活かして、柔軟で信頼できるアーキテクチャを確実にする計画を立てています。
Team #1:
Location: London
Team Lead: Chris
Focus: Weather Service
Language: Groovy
Framework: Oracle Helidon SE with Gradle
Team #2:
Location: Tokyo
Team Lead: Michiko
Focus: Quote Service
Language: Java
Framework: Oracle Helidon MP with Maven
Team #3:
Location: Bangalore
Team Lead: Murielle
Focus: Stock Service
Language: JavaScript/Node
Framework: Express
Team #4:
Location: Melbourne
Team Lead: Dominic
Focus: Cat Picture Service
Language: Java
Framework Oracle Fn (Serverless)
Team #5
Location: Atlanta
Team Lead: Ava
Focus: Frontend
Language: JavaScript/TypeScript
Framework: Angular 6
ご覧のように、Lydiaは幅広いスキルと経験を備えた多種多様なチームを集めています。選択されたものの中には、Oracle以外のテクノロジーもあることにお気づきかと思います。Oracleテクノロジにフォーカスしたブログエントリでは奇妙な点があるかもしれませんが、これは今日の多くのソフトウェア企業の様子を表しています。チームが単一の企業のスタックだけに集中することはほとんどありません。そうしてもらえるといいのですが、現実的には、チームにはその強みと好みがあります。この一連のエントリでは、Oracleの新しいオープンソース・フレームワークであるHelidonとServerlessのためのFn projectを活用して、マイクロサービスとServerless functionをビルドするだけでなく、チームがOracle Cloudに全てのスタックをデプロイできる点をご紹介します。
Helidon
https://helidon.io
Fn Project
https://fnproject.io
Helidonについては、紹介記事よりも少し詳しく紹介しますので、最初に以下の紹介記事とチュートリアルを読んでから、この記事の残りの部分を読んでください。
Helidon Takes Flight
https://medium.com/oracledevs/helidon-takes-flight-fb7e9e390e9c
https://orablogs-jp.blogspot.com/2018/09/helidon-takes-flight.html
Tutorial
http://helidon.io/docs/latest/#/about/01_introduction
Team #1は、ユーザーのいる場所の天気を取得するためのバックエンドの構築を任されています。Team #1はGroovyに強みを持つチームですが、Oracleの新しいマイクロサービスフレームワークであるHelidonについて良い話を聞いたので、この新しいHelidonを学びながら、ビルドツールのGroovyとGradleと一緒に使えるのかを確認することにしました。チームリーダーのChrisはHelidonのチュートリアルを読み、クイックスタートのサンプルを使って新しいアプリケーションを作成しました。
Getting-started — Quickstart Examples
https://helidon.io/docs/latest/#/getting-started/02_base-example
そのため、作成されたJavaアプリケーションをGroovyアプリケーションに変換することが彼の最初の作業です。この場合、Chrisはまず最初にGradleのビルドファイルを作成し、GroovyとHelidonのそれぞれの依存関係が全て含まれていることを確認する必要があります。Chrisはプロジェクトビルド時に依存関係のすべてがプロジェクトのビルド時に必要な場所に配置されるよう、'copyLibs'タスクも追加しておく必要があります。以下はbuild.gradleファイルの例です。
apply plugin: 'java'
apply plugin: 'maven'
apply plugin: 'groovy'
apply plugin: 'application'
mainClassName = 'codes.recursive.weather.Main'
group = 'codes.recursive.weather'
version = '1.0-SNAPSHOT'
description = """A simple weather microservice"""
sourceSets.main.resources.srcDirs = [ "src/main/groovy", "src/main/resources" ]
sourceCompatibility = 1.8
targetCompatibility = 1.8
tasks.withType(JavaCompile) {
options.encoding = 'UTF-8'
}
ext {
helidonversion = '0.10.0'
}
repositories {
maven { url "http://repo.maven.apache.org/maven2" }
mavenLocal()
mavenCentral()
}
configurations {
localGroovyConf
}
dependencies {
localGroovyConf localGroovy()
compile 'org.codehaus.groovy:groovy-all:3.0.0-alpha-3'
compile "io.helidon:helidon-bom:${project.helidonversion}"
compile "io.helidon.webserver:helidon-webserver-bundle:${project.helidonversion}"
compile "io.helidon.config:helidon-config-yaml:${project.helidonversion}"
compile "io.helidon.microprofile.metrics:helidon-metrics-se:${project.helidonversion}"
compile "io.helidon.webserver:helidon-webserver-prometheus:${project.helidonversion}"
compile group: 'com.mashape.unirest', name: 'unirest-java', version: '1.4.9'
testCompile 'org.junit.jupiter:junit-jupiter-api:5.1.0'
}
// define a custom task to copy all dependencies in the runtime classpath
// into build/libs/libs
// uses built-in Copy
task copyLibs(type: Copy) {
from configurations.runtime
into 'build/libs/libs'
}
// add it as a dependency of built-in task 'assemble'
copyLibs.dependsOn jar
copyDocker.dependsOn jar
copyK8s.dependsOn jar
assemble.dependsOn copyLibs
assemble.dependsOn copyDocker
assemble.dependsOn copyK8s
// default jar configuration
// set the main classpath
jar {
archiveName = "${project.name}.jar"
manifest {
attributes ('Main-Class': "${mainClassName}",
'Class-Path': configurations.runtime.files.collect { "libs/$it.name" }.join(' ')
)
}
}
ビルドスクリプトを設定し、Chrisのチームはアプリケーションをビルドします。Helidon SEは、シンプルなサービスを簡単に構築できます。まず始めに、以下のクラスだけが必要です。Main.groovy(GradleスクリプトがMain.groovyへのパスを使ってmainClassNameを識別していることに注目してください)は、サーバーを作成し、ルーティングを設定、エラー処理を設定し、オプションでメトリックを設定します。以下はMain.groovyです。
final class Main {
private Main() { }
private static Routing createRouting() {
MetricsSupport metricsSupport = MetricsSupport.create()
MetricRegistry registry = RegistryFactory
.getRegistryFactory()
.get()
.getRegistry(MetricRegistry.Type.APPLICATION)
return Routing.builder()
.register("/weather", new WeatherService())
.register(metricsSupport)
.error( NotFoundException.class, {req, res, ex ->
res.headers().contentType(MediaType.APPLICATION_JSON)
res.status(404).send(new JsonGenerator.Options().build().toJson(ex))
})
.error( Exception.class, {req, res, ex ->
ex.printStackTrace()
res.headers().contentType(MediaType.APPLICATION_JSON)
res.status(500).send(new JsonGenerator.Options().build().toJson(ex))
})
.build()
}
static void main(final String[] args) throws IOException {
startServer()
}
protected static WebServer startServer() throws IOException {
// load logging configuration
LogManager.getLogManager().readConfiguration(
Main.class.getResourceAsStream("/logging.properties"))
// By default this will pick up application.yaml from the classpath
Config config = Config.create()
// Get webserver config from the "server" section of application.yaml
ServerConfiguration serverConfig =
ServerConfiguration.fromConfig(config.get("server"))
WebServer server = WebServer.create(serverConfig, createRouting())
// Start the server and print some info.
server.start().thenAccept( { NettyWebServer ws ->
println "Web server is running at http://${config.get("server").get("host").asString()}:${config.get("server").get("port").asString()}"
})
// Server threads are not demon. NO need to block. Just react.
server.whenShutdown().thenRun({ it ->
Unirest.shutdown()
println "Web server has been shut down. Goodbye!"
})
return server
}
}
Heldion SEはsrc/main/resourcesにapplication.yamlという名前のYAMLファイルを配置し、このファイルを構成目的で使います。サーバー関連の構成だけでなく、任意のアプリケーションの変数をこのファイルに格納できます。ChrisのチームはAPI関連の変数をこのファイルに記載しています。
app:
apiBaseUrl: "https://api.openweathermap.org/data/2.5"
apiKey: "[redacted]"
server:
port: 8080
host: 0.0.0.0
Mainクラスに戻ると、13行目で/weatherというエンドポイントを登録しており、WeatherServiceを示すことがわかります。このクラスは天気のデータを取得することになったときに働きます。Helidon SEサービスはServiceインターフェースを実装します。このクラスにはupdate()メソッドがあり、このメソッドを使って指定されたサービスへのサブルートを確立し、これらのサービスクラスのプライベート・メソッドでサブルートを指し示します。Chrisのチームは以下のようなupdate()メソッドを作成しました。
void update(Routing.Rules rules) {
rules
.any(this::countAccess as Handler)
.get("/current/city/{city}", this::getByLocation as Handler)
.get("/current/id/{id}", this::getById as Handler)
.get("/current/lat/{lat}/lon/{lon}", this::getByLatLon as Handler)
.get("/current/zip/{zip}", this::getByZip as Handler)
}
Chrisのチームは、消費者に現在の天気を(都市、ID、緯度/経度または郵便番号)という4つの別々の方法で提供する4個の異なるルートを"/weather"配下に作成します。Groovyを使っているので、メソッド参照をio.helidon.webserver.Handlerとしてキャストする必要があります(キャストしないと例外が発生します)。メソッドの一つであるgetByZip()を見てみましょう。
private void getByZip(ServerRequest request, ServerResponse response) {
def zip = request.path().param("zip")
def weather = getWeather([ (ZIP): zip ])
response.headers().contentType(MediaType.APPLICATION_JSON)
response.send(weather.getBody().getObject().toString())
}
getByZip()メソッドはパラメータZip(郵便番号)をリクエストから拾いだし、getWeather()を呼び出します。この際にUnirestと呼ばれるクライアントライブラリを使って選択したweather APIへのHTTP呼び出しを行い、現在の天気をgetByZip()に返し、JSONとしてブラウザにレスポンスを送信します。
Unirest for Java
http://unirest.io/java.html
private HttpResponse<JsonNode> getWeather(Map params) {
return Unirest
.get("${baseUrl}/weather?${params.collect { it }.join('&')}&appid=${apiKey}")
.asJson()
}
ご覧の通り、ルータが呼び出した際に各サービスメソッドは、渡ってきた2個の引数であるリクエストとレスポンス(以前マイクロサービス・フレームワークを使ったことがあれば推測できるかと思いますが)を取得します。これらの引数を使って開発者はURLパラメータ、フォームデータ、HTTPヘッダーをリクエストから取得し、ステータス、メッセージ本体、HTTPヘッダーを必要に応じてレスポンスに設定します。このチームがweatherサービスの全体を構築すると、Gradleのrunタスクを実行して全てがブラウザで問題なく動作するか確認する準備ができあがります。

ロンドンは曇ですか…。
Helidon SEには他にも色々ありますが、おわかりの通り、基本的なマイクロサービスを稼働させるためには多くのコードを必要としません。後のエントリでサービスのデプロイ方法を見ていきますが、Helidonは手順を簡単にするために、DockerfileとKubernetesの設定ファイルの作成をサポートしています。
ではMichikoのチームを見てみましょう。このチームにはランダムに名言(Quote)を返すバックエンドの構築を任されています。このような機能がなければパーソナライズされたホームページではないためです。この東京のチームはJavaでコードを作成し、Mavenを使用してコンパイルと依存関係を管理していて、MicroProfileのAPIのことをよく知っています。
MicroProfile
https://microprofile.io/
MichikoとそのチームもHelidonを使用することに決めましたが、MicroProfileに詳しいため、よりリアクティブで関数型スタイルを使うSEではなく、長年使ってきたJAX-RSやCDIのようなよく知っているAPIを提供していることから、Helidon MPを使うことに決めました。Chrisのチームのように、MPのquickstart archetypeを使ってスケルトンアプリケーションをさくっと作成し、Main.javaクラスの設定を開始します。
Getting-started — Quickstart Examples
https://helidon.io/docs/latest/#/getting-started/02_base-example
M ainクラスの主なメソッドはstartServer()を呼び出します。このメソッドはSEのメソッドとは若干異なりますが、同じタスクを実行します。具体的には構成ファイル(/src/main/resources/META-INF にあるmicroprofile-config.propertiesというファイル)を使ってアプリケーションサーバを起動します。
protected static Server startServer() throws IOException {
// load logging configuration
LogManager.getLogManager().readConfiguration(
Main.class.getResourceAsStream("/logging.properties"));
// Server will automatically pick up configuration from
// microprofile-config.properties
Server server = Server.create();
server.start();
return server;
}
続いて、CDI実装がクラスを拾い上げることができるよう、 /src/main/resources/META-INF にbeans.xmlを作成します。
<!--?xml version="1.0" encoding="UTF-8"?-->
<beans>
</beans>
JAX-RSアプリケーションを作成し、必要に応じてリソースクラスを追加します。
@ApplicationScoped
@ApplicationPath("/")
public class QuoteApplication extends Application {
@Override
public Set<Class<?>> getClasses() {
Set<Class<?>> set = new HashSet<>();
set.add(QuoteResource.class);
return Collections.unmodifiableSet(set);
}
}
QuoteResourceクラスを作成します。
@Path("/quote")
@RequestScoped
public class QuoteResource {
private static String apiBaseUrl = null;
@Inject
public QuoteResource(@ConfigProperty(name = "app.api.baseUrl") final String apiBaseUrl) {
if (this.apiBaseUrl == null) {
this.apiBaseUrl = apiBaseUrl;
}
}
@SuppressWarnings("checkstyle:designforextension")
@Path("/random")
@GET
@Produces(MediaType.APPLICATION_JSON)
public String getRandomQuote() throws UnirestException {
String url = apiBaseUrl + "/posts?filter[orderby]=rand&filter[posts_per_page]=1";
HttpResponse<JsonNode> quote = Unirest.get(url).asJson();
return quote.getBody().toString();
}
}
構成プロパティを取得するためにコンストラクタインジェクションを使用し、パスやHTTPメソッド、レスポンスのContent Typeのためにシンプルなアノテーションを使っている点に注目してください。getRandomQuote()メソッドはUnirestを使ってquote APIを呼び出し、結果をJSON文字列として戻します。mvnパッケージタスクを実行し、結果として生じるJARを実行すると、アプリケーションが起動し、以下のような結果が得られます。

ユーザベースの拡大と興奮した投資家からの追加資金の調達に伴い、時間の経過とともにサービスが成長する柔軟な基盤上に、Michikoのチームは名言のマイクロサービスの初期実装を成功裏に構築しました。SEバージョンと同様、Helidon MPはデプロイの一助となるDockerfileとKubernetesのapp.yamlファイルを生成します。後ほどデプロイを見ていきましょう。
このエントリでは、莫大な資金を調達した、インターネット・ホームページ・アプリケーションのためのマイクロサービスに踏み入ったの架空のスタートアップ企業について説明しました。Helidonというマイクロサービス・フレームワークは、リアクティブで関数型のスタイルを提供するバージョンだけでなく、JAX-RSやCDIに慣れ親しんだJava EEの開発者により適したMicroProfileバージョンも提供していることを知りました。Lydiaのチームは、バックエンドのアーキテクチャの構築を急速に進めており、
TechCorpのビジョンを実現するのにもう少しの所まで近づいています。次回のエントリでは、MurielleとDominicのチームがサービスをどのように構築するのかを見ていきます。将来のエントリでは、すべてのチームが最終的にどのようにサービスをテストし、運用に入っていくのかを見ていくことにしています。